- Persistent Context 란
- Entity Life Cycle
- CRUD 상황별 Persistent Context 에서의 상황 정리
- 조회
- 삽입
- 수정
- 삭제
- JPA repository.save() 시 발생하는 내부 동작 (persist vs merge)
- entityManager.flush()
Persistent Context 란
오라클 공식 문서에 따르면 아래와 같이 정의되어 있다. 요약하면 ‘a set of entity instances’ 이다.
A persistence context is a set of entity instances in which for any persistent entity identity there is a unique entity instance.
논리적으로 1차 캐시와 크게 다를바가 없다. 하지만 대놓고 1차 캐시라고 표현하고 있지는 않다.
밸덩 에서는 대놓고 1차 캐시라고 표현하고 있다.
The persistence context is the first-level cache where all the entities are fetched from the database or saved to the database. It sits between our application and persistent storage.
책에서는 ‘엔티티를 영구 저장하는 환경’ 이라는 표현을 사용하고 있는데 확실하게 와닿지는 않는다.
‘Entity Manager가 영속성 관리를 목적으로 사용하는 공간’이라고 이해하는 것이 좋을 것 같다. 영속성 컨텍스트(Persistent Context)에 관해서 책에서 나온 모든 개념을 넣은 그림은 아래와 같다.

책에 따르면 EntityManager 와 Persistent Context 의 생명주기가 같다.
‘엔티니 매니저를 만들면 그 내부에 영속성 컨텍스트도 함께 만들어진다. 이 영속성 컨텍스트는 엔티티 매니저를 통해서 접근할 수 있다.’
Entity Life Cycle
백기선님 강의 보며 정리했던걸 그대로 사용한다. 책과 그림이 좀 다른데 이미 익혀둔 것을 기준으로 삼는게 좋을 것 같다.
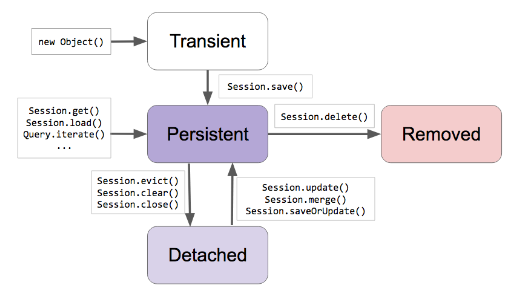
출처 : 강의자료
*[Transient] : 임시로 체류중인 상태로 JPA가 관심을 두지 않는 상태(관리 X)
*[Persistent] : JPA가 해당 Entity 에 대해 관심을 두고 관리중인 상태(관리 O)
*Detached : JPA가 더이상 해당 Entity 에 대해 관심을 두지 않지 않는 상태(관리 X)
*Removed : JPA가 관리하긴 하지만 삭제하기로 한 상태(Removed 상태라고 해서 아직 delete 쿼리가 수행된 것은 아니지만 영속성 컨텍스트에서 삭제된 상태가 된다)
DML 수행시 Persistent Context 에서의 상황 정리
조회
entityManager.find(Post.class, 1L);
- 위와 같이 엔티티 매니저가 조회를 수행할 때는 먼저 1차 캐시를 PK 값을 기준으로 조회한다.
- 1차 캐시에 데이터가 있는 경우 1차 캐시에 있는(= 영속 상태의) Entity 를 반환한다.
- 1차 캐시에 데이터가 없는 경우 Database를 조회하고 값을 가져와 1차 캐시에 저장(= 영속 상태)하고 Persistent 상태가 된 해당 Entity 를 반환한다.
삽입
Post post1 = new Post();
post1.setName("포스트이름 1");
post1.setDescription("포스트상세설명 1");
Post post2 = new Post();
post2.setName("포스트이름 2");
post2.setDescription("포스트상세설명 2");
entityManager.persist(post1);
entityManager.persist(post2);
- persist 가 수행되면 transient 상태의 객체가 1차 캐시에 저장(= 영속 상태) 된다.
- 쓰기 지연 SQL 로 해당 entity 에 대한 insert 문이 저장된다.
- 트랜젝션이 끝나면서 flush 가 수행되며 database 에 쓰기 지연 SQL 에 저장된 모든 쿼리를 수행요청 한다. (transactional write behind)
GeneratedValue 전략이 IDENTITY 인 경우에는 영속성 컨텍스트 저장을 위한 ID 값 채번이 필요하므로 persist 발생과 동시에 insert 가 실행된다.
수정
Post fisrtPost = entityManager.find(Post.class, 1L);
fisrtPost.setDescription("상세설명을 변경처리");
- 조회 요청으로 1차 캐시에 없는 경우 database 에서 Entity 가져온다.
- 가져온 Entity를 1차 캐시에 저장하며 Entity 의 Snapshot 도 같이 저장해둔다.
- 로직에 의해 Entity 의 변경이 발생한다(1차 캐시 내에서)
- 커밋되는 시점에 Entity vs Snapshot 비교 후 Snapshot 과 다를 경우 Entity 를 최신이라 판단하고 Entity 에 맞게 update 문을 쓰기 지연 sql 에 저장한다. (dirty checking)
- flush 발생하며 일괄적으로 database 에 sql 이 수행 요청 된다.
삭제
Post post = entityManager.find(Post.class, 2L);
System.out.println(">>> " + entityManager.contains(post));
System.out.println("====================================");
entityManager.remove(post);
System.out.println(">>> " + entityManager.contains(post));
Hibernate:
select
post0_.id as id1_0_0_,
post0_.description as descript2_0_0_,
post0_.name as name3_0_0_
from
post post0_
where
post0_.id=?
2022-12-27 13:48:16.190 TRACE 56861 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [2]
2022-12-27 13:48:16.206 TRACE 56861 --- [ main] o.h.type.descriptor.sql.BasicExtractor : extracted value ([descript2_0_0_] : [VARCHAR]) - [첫번째 포스트 상세]
2022-12-27 13:48:16.206 TRACE 56861 --- [ main] o.h.type.descriptor.sql.BasicExtractor : extracted value ([name3_0_0_] : [VARCHAR]) - [첫번째 포스트 이름]
>>> true
====================================
>>> false
Hibernate:
delete
from
post
where
id=?
2022-12-27 13:48:16.240 TRACE 56861 --- [ main] o.h.type.descriptor.sql.BasicBinder : binding parameter [1] as [BIGINT] - [2]
- entityManager.remove(E) 가 요청되는 순간 영속 상태가 해제되고 쓰기 지연 sql 에 delete 문이 저장된다.
- 트랜젝션 종료되며 flush 발생하고 쓰기 지연 sql 에 저장된 쿼리가 database 에 수행 요청 된다.
JPA repository.save() 시 발생하는 내부 동작 (persist vs merge)
repositoy의 save() 구현체를 보면 아래와 같다.
/*
* (non-Javadoc)
* @see org.springframework.data.repository.CrudRepository#save(java.lang.Object)
*/
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}
새로운 entity 면 persist 이고 존재하는 entity 면 merge 를 해주고 있는데, 이 차이를 유심히 봐둬야하나?
그렇다. 왜냐햐면 persist 의 경우에 파라미터로 들어온 entity 자체를 영속화 해주는데 반해 merge 의 경우 파라미터로 들어온 entity 의 복사본을 영속화하고 그렇게 영속화 한 entity 를 return 해주기 때문이다.
이를 알아둬야 하는 이유는 실제 로직에서 update 발생시 이후에 뭔가 비즈니스 로직 처리를 해야할 때 파라미터로 보낸 entity 를 사용해선 안되고 return 받은 그 entity 를 사용해야 하는 것의 근거이기 때문이다.
entityManager.flush()
/**
* Synchronize the persistence context to the
* underlying database.
* @throws TransactionRequiredException if there is
* no transaction or if the entity manager has not been
* joined to the current transaction
* @throws PersistenceException if the flush fails
*/
public void flush();
entityManager의 flush() 가 호출되면 1차 캐시는 비워지지 않고 쓰기 지연 SQL 에 담긴 모든 sql 이 실행된다.