강의 자료에 정리가 아주 깔끔하게 잘 되어있고, 굳이 옮겨올 필요성을 못느껴서 실습하면서 정말 남기고 싶은 기록만 남겼다. 그러므로 복습시 꼭 강의자료 링크를 들어가서 내용을 전부 다시 숙지하도록 한다.
- 기본 명령어
- Pod
- ReplicaSet
- Deployment
- Service
- Ingress
- Volume
- ConfigMap
- Secret
기본 명령어
강의 자료 참고
Pod
강의 자료 참고
- readinessProbe 설정을 해주지 않으면 기본적으로 모든 pod 에 다 요청을 하고, readinessProbe 설정을 해주면 readinessProbe 에 통과한 pod 에만 요청을 보내준다.
- 보통은 livenessProbe, readinessProbe 모두 적용 한다고 한다.(강의 자료 참고)
- 정상 여부 판단 방법은 path 를 명시 했을때와 안했을때가 다르다.(실제로 이건 해보면서 확인을 해보자)
- path 명시할 경우 해당 요청을 실제로 보내서 응답코드 200 으로 판단한다.
- path 를 생략할 경우 해당 포트에 TCP 소켓 연결만을 확인한다. 해당 포트에서 수신 대기중이면 정상 상태라고 간주한다.
아래는 chatGPT 로 공부하던거 발췌
LivenessProbe와 ReadinessProbe에서 설정한 대로 체크를 할 때, 정상 여부는 Probe에서 사용하는 확인 방법에 따라 결정됩니다.
LivenessProbe는 컨테이너의 상태를 지속적으로 확인하며, 컨테이너가 살아있는지 여부를 판단합니다. LivenessProbe에서는 주로 컨테이너 내부의 프로세스 상태를 체크하거나, 네트워크 상태를 확인하는 방법을 사용합니다. 예를 들어, HTTP GET 요청을 보내서 응답을 확인하는 방법이 사용될 수 있습니다. 만약 LivenessProbe에서 지정한 확인 방법에 실패하면, Kubernetes는 해당 컨테이너를 다시 시작합니다.
ReadinessProbe는 컨테이너가 서비스 요청을 처리할 준비가 되었는지 여부를 판단합니다. ReadinessProbe에서는 주로 컨테이너가 사용하는 포트가 열려 있는지 여부를 확인하는 방법이 사용됩니다. 예를 들어, TCP 소켓 연결을 시도하고 연결이 성공하면 준비 상태로 판단할 수 있습니다. 만약 ReadinessProbe에서 지정한 확인 방법에 실패하면, 해당 컨테이너로의 서비스 요청은 전달되지 않습니다.
따라서, LivenessProbe와 ReadinessProbe에서 지정한 확인 방법이 성공하면, Kubernetes는 해당 컨테이너가 정상 상태로 간주합니다. 실패하면, Kubernetes는 해당 컨테이너를 다시 시작하거나, 서비스 요청을 전달하지 않습니다.
apiVersion: v1
kind: Pod
metadata:
name: echo-health
labels:
app: echo
spec:
containers:
- name: app
image: ghcr.io/subicura/echo:v1
livenessProbe:
httpGet:
path: /
port: 3000
readinessProbe:
httpGet:
path: /
port: 3000
ReplicaSet
강의 자료 참고
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: echo-rs
spec:
replicas: 1
selector:
matchLabels:
app: echo
tier: app
template:
metadata:
labels:
app: echo
tier: app
spec:
containers:
- name: echo
image: ghcr.io/subicura/echo:v1
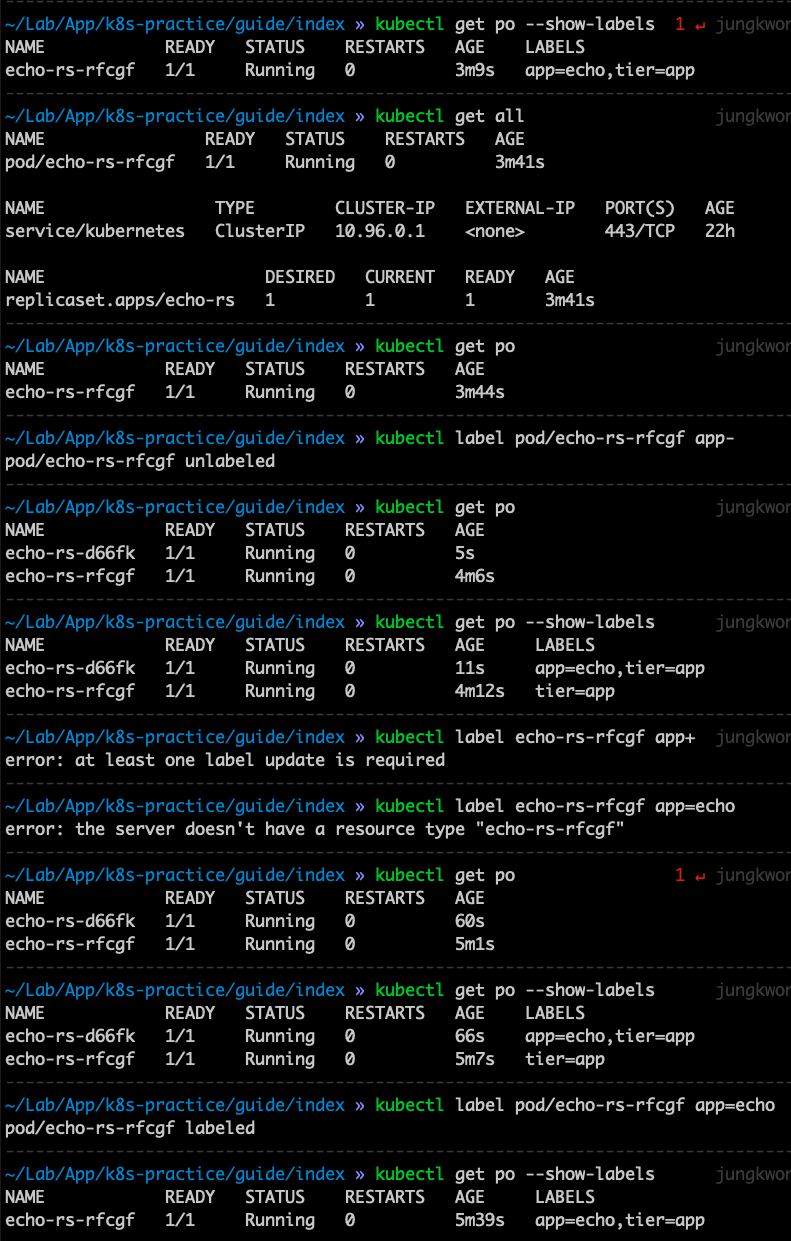
스크립트를 보면 알 수 있듯이 label 을 없애면 desired state 가 아니기 때문에 하나를 만드는데, 신기한건 없앤 것에 label 을 다시 추가해주면 두 개가 되니까 또 desired state 이 아니니까 하나를 없앤다.
Deployment
강의 자료 참고
배포를 이렇게 깔끔하게 해주는게 정말 놀랍다. 배포 전략에 관해서 용어가 일반적으로 사용하는 것과 약간의 차이가 있어 따로 정리한다.
Kubernetes에서는 Deployment, StatefulSet, DaemonSet 등 여러 가지 리소스를 사용하여 애플리케이션을 배포할 수 있습니다. 각 리소스는 배포 전략(strategy)을 지정할 수 있습니다. Deployment 리소스를 예로 들면, Deployment 리소스에서 사용할 수 있는 배포 전략은 다음과 같습니다.
RollingUpdate
새로운 버전의 Pod을 하나씩 배포하면서 기존 버전의 Pod을 제거하는 방식으로 배포합니다. 이 방식은 서비스 중단 시간을 최소화할 수 있습니다. RollingUpdate 전략에서는 maxSurge와 maxUnavailable 파라미터를 조정하여 배포 시 서비스 중단 시간과 버전 간 전환 시간을 조절할 수 있습니다.
-
maxSurge RollingUpdate 전략을 사용하여 새로운 버전의 Pod을 배포할 때, 한 번에 생성할 수 있는 최대 Pod 개수를 지정합니다. 기본값은 25%이며, spec.strategy.rollingUpdate.maxSurge로 설정할 수 있습니다. 이 값을 0으로 설정하면 새로운 Pod을 생성하지 않습니다. 만약 maxSurge 값을 1로 설정하면 기존에 있는 Pod 개수에 상관없이 1개의 Pod을 추가로 생성할 수 있습니다.
-
maxUnavailable RollingUpdate 전략을 사용하여 새로운 버전의 Pod을 배포할 때, 동시에 사용할 수 없는 최대 Pod 개수를 지정합니다. 기본값은 25%이며, spec.strategy.rollingUpdate.maxUnavailable로 설정할 수 있습니다. 이 값을 0으로 설정하면 동시에 사용할 수 없는 Pod이 없습니다. 만약 maxUnavailable 값을 1로 설정하면 기존에 있는 Pod 개수에 상관없이 1개의 Pod이 사용할 수 없게 됩니다.
예를 들어, maxSurge를 1로, maxUnavailable을 0으로 설정하면, 하나의 Pod을 추가로 생성한 후에 기존 Pod을 하나씩 삭제하여 새로운 버전의 Pod으로 전환합니다. 만약 maxSurge를 25%로, maxUnavailable을 25%로 설정하면, 최대 25%까지는 추가로 Pod을 생성하고, 최대 25%까지는 사용할 수 없게 만들어 기존 버전의 Pod 중 일부가 사용되지 않게 됩니다. 이렇게 함으로써, 새로운 버전의 Pod을 전환하는 동안에도 기존 버전의 Pod을 사용할 수 있게 됩니다.
Recreate
새로운 버전의 Pod을 모두 생성한 후, 기존 버전의 Pod을 모두 제거하는 방식으로 배포합니다. 이 방식은 RollingUpdate에 비해 서비스 중단 시간이 길지만, 전환 시간이 짧습니다.
Service
강의 자료 참고
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis
spec:
selector:
matchLabels:
app: counter
tier: db
template:
metadata:
labels:
app: counter
tier: db
spec:
containers:
- name: redis
image: redis
ports:
- containerPort: 6379
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: redis
spec:
ports:
- port: 6379
protocol: TCP
selector:
app: counter
tier: db
여기서 Service 의 아래 부분을 보자.
spec:
ports:
- port: 6379
protocol: TCP
- spec.ports.port : 서비스가 생성할 Port
- spec.ports.targetPort : 서비스가 접근할 Pod의 Port (기본: port랑 동일)
- spec.selector : 서비스가 접근할 Pod의 label 조건
targetPort 는 생략할 수 있다. 지금 Deployment 의 컨테이너의 containerPort 와 Service 의 포트가 동일해서 헷갈릴 수 있는데, Service 의 port(spec.ports.port) 는 서비스가 생성하여 노출할(이 포트로 붙어야 해당 서비스로 붙는 것) 포트이다.
그리고 spec.ports.targetPort(위에서 명시는 생략한) 는 ‘이 서비스로 들어왔을때 내부적으로 어느 포트를 바라볼지’ 에 대한 설정이다. 여기서는 컨테이너의 포트를 6379 로 했기 때문에 spec.ports.port 과 동일하게 바라봐야하니까 spec.ports.targetPort 를 생략할 수 있었다.
쿠버네티스에서 kind가 Service일 때, spec의 type은 서비스를 어떻게 노출할 것인지를 결정하는 중요한 옵션입니다. 다음과 같은 타입을 설정할 수 있습니다.
-
ClusterIP : 기본 값이며, 쿠버네티스 내부에서만 접근 가능한 IP를 할당합니다.
-
NodePort : 클러스터 내의 모든 노드에 대해 포트를 열어서 외부에서 접근할 수 있도록 합니다.
-
LoadBalancer : 클라우드 제공업체에서 제공하는 로드밸런서를 사용하여 외부에서 서비스에 접근할 수 있도록 합니다.
-
ExternalName : DNS 항목을 노출하여 서비스 이름으로 외부 리소스를 참조할 수 있도록 합니다.
왜 예제에서 LoadBalancer 설정시 port 를 NortPort 를 바라보게 하지 않고 spec.ports.port 를 바라보게 했을까? 이건 한번 나중에 찾아봐야겠다.
지금 이 상황은 아무래도 minikube 를 사용하는 상황이기 때문에 단일 노드 클러스터라서 로드밸런서가 바라볼때 노드포트가 아니라 노드 내 파드의 포트를 바라보게 해야해서 그런 것 같은데, 나중에 쿠버네티스 입문 책 보면서 할 때 설정을 어떻게 하는지 다시 보고 지금은 넘어가도록 한다.
Ingress
강의 자료 참고
Ingress 는 내부적으로 결국 nginx 를 사용하고 있다. 강의 12:05 부분에서도 나오는데 Ingress nginx controller 컨테이너에 접속을 하면 nginx conf 를 확인할 수 있는데, 내용을 확인해보면 Ingress 를 띄울때 사용한 yml 파일 내용대로 도메인에 따라 분기처리하고 있는 것을 확인할 수 있다. 강의 자료에도 나와있지만 결국 Ingress 의 설정 내용대로 nginx 를 구성하고 있고, Ingress 설정이 바뀌면 바뀐대로 nginx 를 다시 구성해서 띄워주는 것이다.
Volume
강의 자료 참고
ConfigMap
강의 자료 참고
Secret
강의 자료 참고
암호화 되어 저장되진 않는다.